入门介绍(Introduction)
大语言模型的输出可能受到配置超参数的影响,这些超参数控制模型的各个方面,例如它有多“随机”。这些超参数可以进行调整,以产生更有创意、更多样化和更有趣的输出。在本节中,我们将讨论两个重要的配置超参数,以及它们如何影响l大语言模型的输出。
备注:
【对于研究员来说】这些不同于常规的超参数,如学习率、层数、隐藏大小等。
温度(Temperature)
温度是一个控制语言模型输出随机性的配置超参数。高温会产生更多不可预测和创造性的结果,而低温则会产生更常见和保守的输出。例如,如果将温度调整为0.5,模型生成的文本通常比将温度设置为1.0更具可预测性,但缺乏创造性。
(Top p)
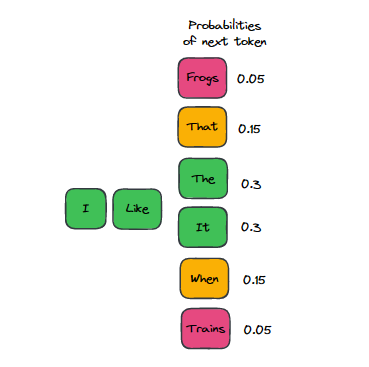
Top p,也称为核采样,是另一个控制语言模型输出随机性的配置超参数。它设置一个阈值概率,并选择累积概率超过阈值的顶部令牌。然后,该模型从这组令牌中随机抽取样本以生成输出。与传统的随机抽样整个词汇表的方法相比,这种方法可以产生更多样化和更有趣的输出。例如,如果你设置top p为0.9,模型将只考虑占概率质量90%的最有可能的单词。
这些超参数如何影响输出(How these hyperparameters affect the output)
温度和top p都可以通过控制生成文本的随机性和多样性的程度来影响语言模型的输出。高温或top p值会产生更多不可预测和有趣的结果,但也会增加错误或无意义文本的可能性。较低的温度或top p值可以产生更保守和可预测的结果,但也可能导致重复或无趣的文本。
对于文本生成任务,您可能希望使用高温或top p值。然而,对于准确性很重要的任务,如翻译任务或问题回答,应该使用低温或最高p值来提高准确性和事实的正确性。
备注:
有时,在配合特殊提示技术时,更多的随机性有助于完成需要准确性的任务。
结论(Conclusion)
总之,温度、top p和其他模型配置超参数是使用语言模型时需要考虑的关键因素。通过理解这些超参数和模型输出之间的关系,从业人员可以优化针对特定任务和应用程序的提示。
备注:
有些模型(如ChatGPT)不允许您调整这些配置超参数。